
Introduction to Machine Learning
Attention needed
This post hasn't been reviewed or updated since it was first written.
Abstract
Machine Learning (ML) is a subfield of Artificial Intelligence (AI) that involves designing systems that are able to recognize patterns and train itself without being explicitly programmed. Machine learning has been involved in many fields and domains. This paper will try to focus on the algorithms and techniques that are being used in the context of improving sales in public retail stores. I will detail the main corpus of the algorithm logic and its type to relatively introduce new researchers to the field
Introduction
Machine learning has been involved in so many fields and domains. Machine Learning (ML) is subfield of Artificial Intelligence (AI) in which systems are designed to be able to recognize the patterns in the data and improve its experience into a learning model that can be applied to new sets of data providing new insights and results that wouldn’t be easily retrievable elsehow.
Tom M. Mitchel, one of the pioneers and main contributors to the field of machine learning and the chair of Machine Learning at Carnegie Mellon University, defines machine learning as a system that “learns from experience E with respect to some class of tasks T and performance measure P, if its performance P at tasks in T, as measured by P, improves with experience E.” (Mitchell, 1997)
Machine Learning, however, is only as good as its training data and multiple algorithms were found to have completely different results depending on the training datasets fed to the system. An understanding of the mathematical foundation of the algorithms is important to understand how the algorithm can be implemented as accurate, and efficient, as the algorithm can be.
Machine Learning Algorithm Types by Learning Style.
While people have longed for computers to be able to learn as well as they do, only certain types of learning tasks were achieved towards that goal. These learning types are chiefly classified into two main classes of learning experience: Supervised and Unsupervised learning. New types have also emerged from combining the types into what’s become known as Semi- Supervised Learning.
Supervised Learning
In supervised learning, the system is provided with datasets of inputs and outputs of known attributes and properties and the system is developed to learn from the training datasets to come up with a mapping function. The system then becomes able to determine the correct output has it been fed with new datasets of unknown outputs. Classification and Regression algorithms are examples of supervised learning. Classification algorithms are used to categorize inputs into known sets of discrete categories or classes. Regression, however, is used when the outputs are expected to be continuous values rather than groups.
Unsupervised Learning
Unsupervised learning is performed when no certain type of output is expected. The system is not provided with the correct response. Instead, it tries to unearth the hidden patterns of the provided training sets (Marsland, 2015). Unsupervised learning is mostly utilized in data mining applications, and some even believe that it is more of data mining than of machine learning (Bell, 2014). An example of this type is the Clustering algorithms. The next sections will discuss various machine learning algorithms, providing a brief description, advantages, and limitations, as well as some current and potential applications of the algorithm in the context of public retail businesses.
Machine Learning ALgorithms
Neural Networks
Artificial Neural Networks (ANN), or Neural Networks for short, was first modeled upon the architecture of the human brain’s neurons; neurons are interconnected together with axons in a way that data and inputs propagates through them while being processed. Analogically, nodes are related together through sets of adaptive weights (axons) that are adjusted as the algorithm learns and adapt to the input data.
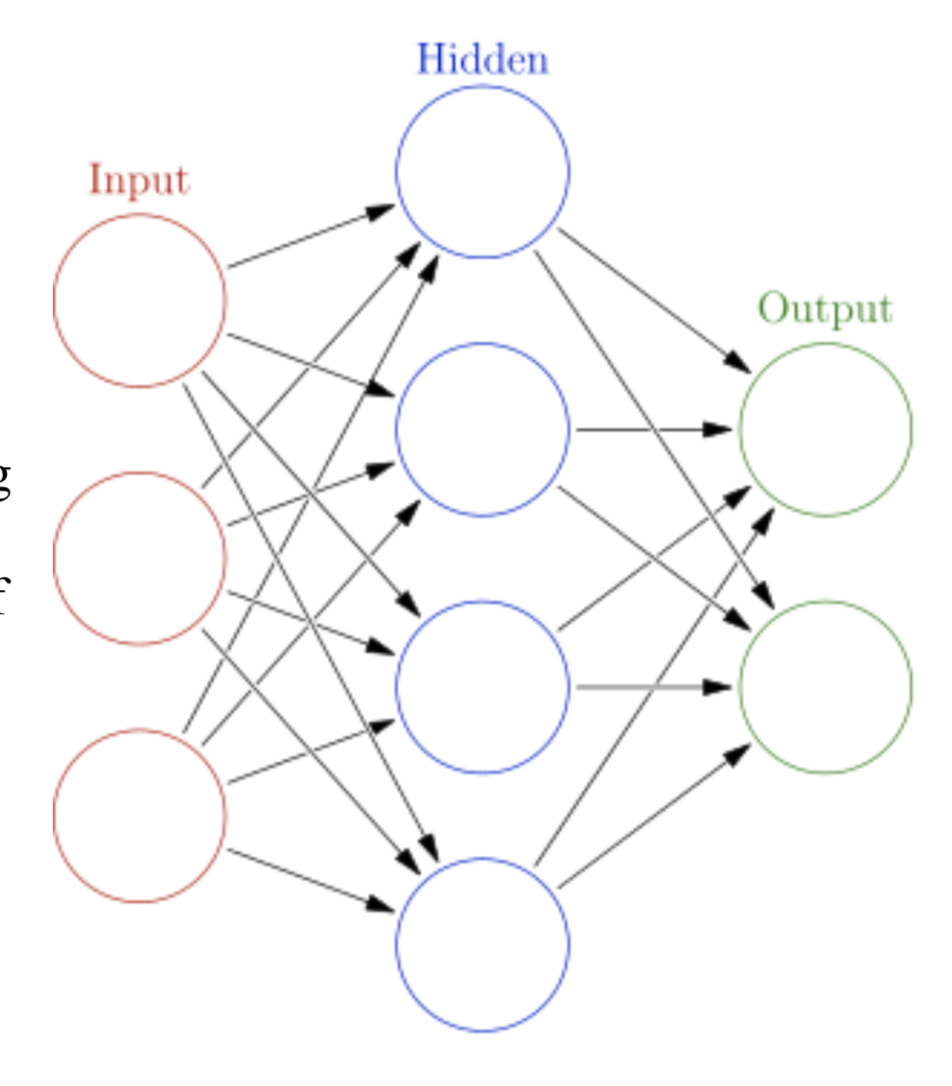
Neural Networks algorithm has various types of learning paradigms and styles that allow them to be classified as either supervised or unsupervised. Backpropagation is one of the learning paradigms widely used in many artificial intelligence applications. The learning process is done in two stages: feed-forward propagation, in which inputs are fed to the randomly- weighted neurons, and secondly, the backward propagation, in which error is calculated as the difference between the anticipated and the actual outputs. The algorithm then uses a gradient descent optimization function iteratively to reduce that deviation from the actual to expected results, and updates the weights accordingly (Marsland, 2015).
Neural Networks had evolved extensively into many forms such as back-propagation such as Perceptron, Hopfield Network, and Radial Basis Function Network (RBFN). NN algorithms have been employed in a vast array of applications such as regression analysis or function approximation due to its capability of approximating non-linear functions. Neural Networks algorithms are also used in classification, and pattern recognition problems. Manyresearch projects have been conducted in the field of sales forecasting using neural networks combined with other clustering and extreme learning machine algorithms and techniques (Lu & Kao, 2016). However, as discussed, since NN implements gradient decent as its optimization function, it’s possible for it to get trapped in and local minima that are not necessarily the global minimum error causing the function not to converge to the desired function.(Mitchell, 1997).
Clustering
One of the crucial tasks of data mining and machine learning is to be able to classify large sets of data group them clusters and categories that can stimulate further insights and from the data. Clustering is an unsupervised learning problem in which the algorithm is only provided with input and is trained to analyze the properties of the provided elements to find the similarities between them and cluster them based on them. It’s different from classification algorithms in the sense that it doesn’t know what the possible classes can be (Bose & Mahapatra, 2001). Clustering helps in the discovery of new unknown but useful classes and categories (Maglogiannis, 2007).
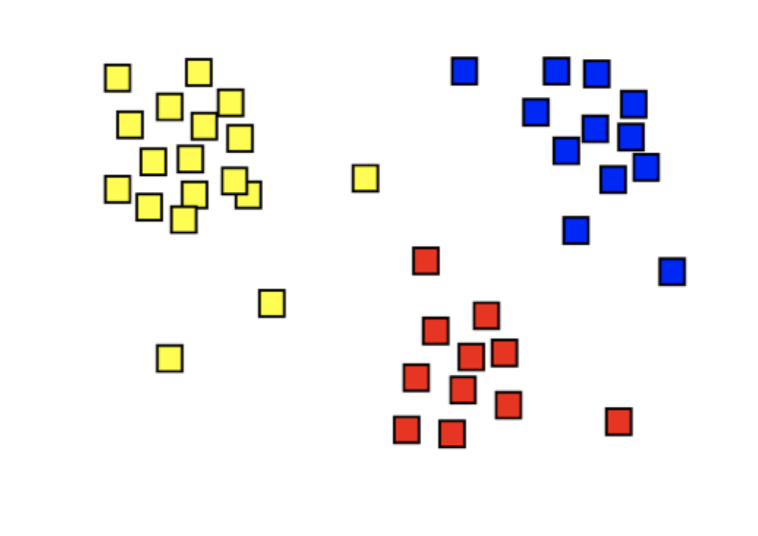
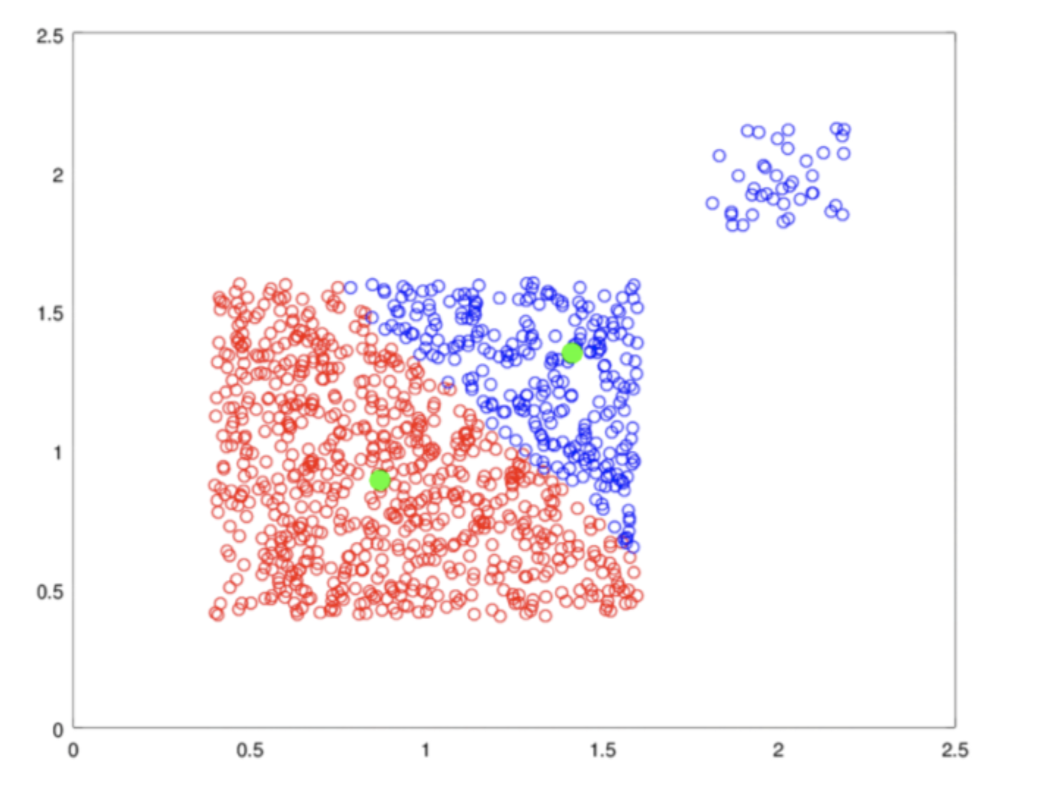
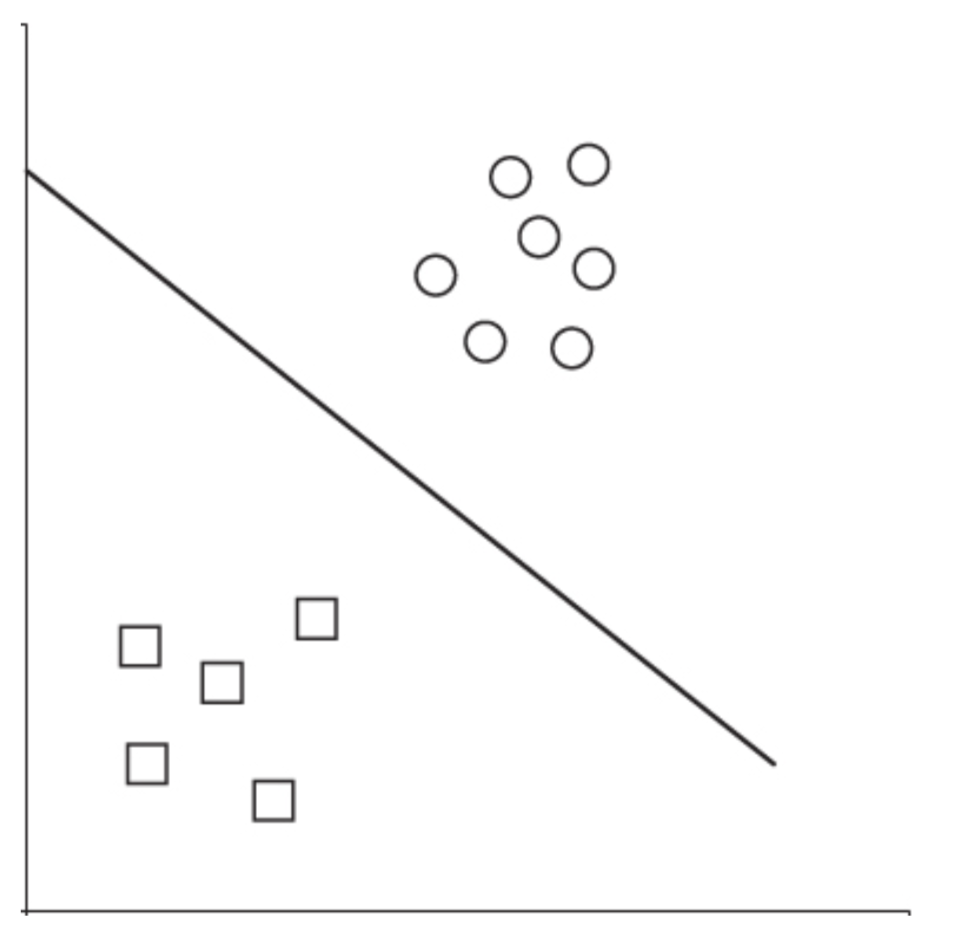
Clustering techniques can be classified into two main categories based on the clustering criteria: connectivity and compactness. K-means is one of the compactness-clustering algorithms. “The aim of the K-mean algorithm is to divide M points in N dimensions into K clusters so that the within-cluster sum of squares is minimized” (Hartigan & Wong, 1979). K- means starts by initializing K centroids from which the distance to the points is to be calculated. The algorithm runs iteratively to reduce the distances to the centroids. The process continues running, recalculating and updating the positon of the centroids until the points no longer fluctuate between the centroids and then it can be assumed that the clustering process is complete (Bell, 2014). K-means, however, have some limitations and deficiencies: K-means clustering model relies upon reducing the distances to the centroid and not on closeness to the neighboring points (Wu, 2012). K-means algorithm also tends to create clusters of similar sizes. These factors together may result into misclassifying the points as shown in the figure. Though, there exists two visual clusters, K-means doesn’t always perform as expected with datasets that can potentially have clusters of different densities and sizes.
Clustering algorithms is often used, in the context of public retail sales improvements, to discover customers’ buying patterns or to reclassify their branches and stores into new classes and clusters to at which different marketing strategies can be performed.
Support Vector Machines
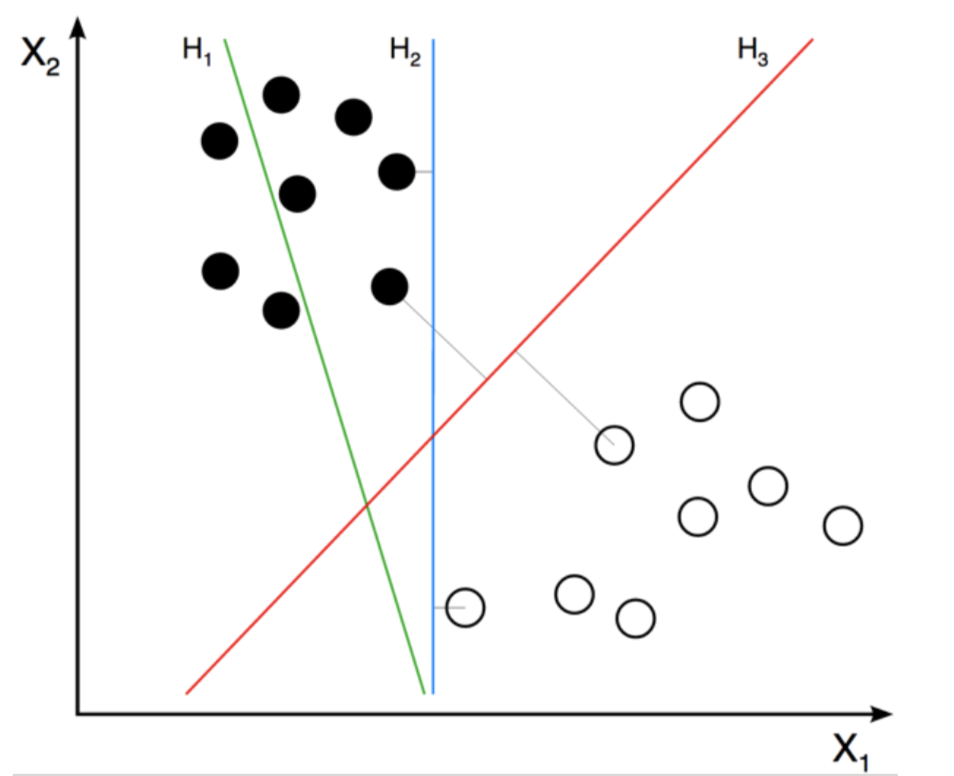
Support Vector Machine (SVM) is an algorithm that, given labeled datasets (supervised learning algorithm) can be used for classification and regression analysis applications (Bell, 2014; Marsland, 2015). It’s different from the afore-discussed k-means algorithm in the overall task definition, learning style type, and the nature of algorithm itself. While other clustering algorithms tend to cluster the elements around the centroid of each class, SVM tries to find the decision boundary between the classes where the items of each class are, theoretically, separated entirely by a margined decision line. The algorithm thus defines what the attributes of the classes are rather than classifying the elements based on what the common element looks like.
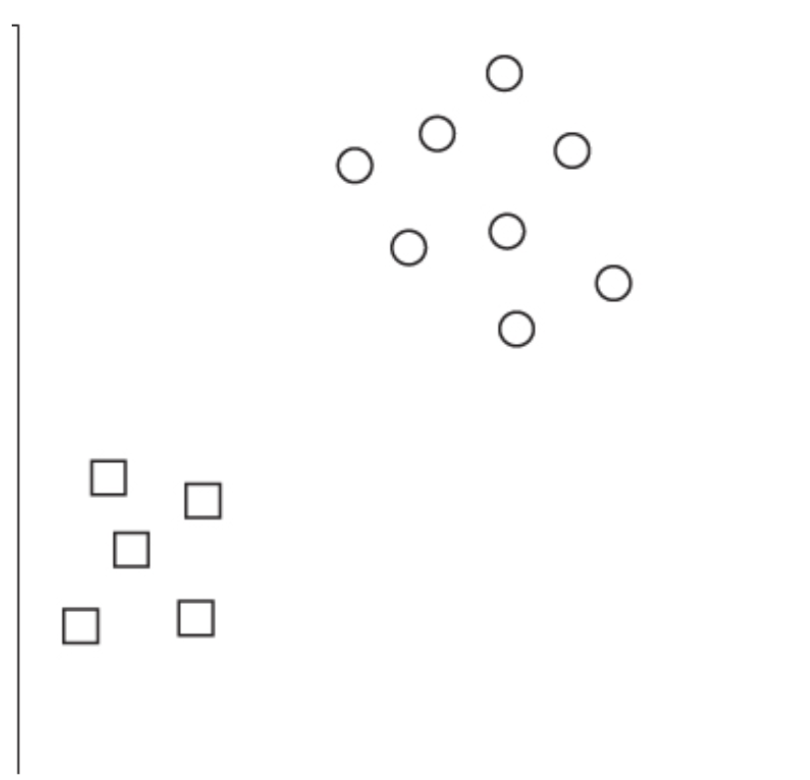
The algorithm was first introduced by Vladimir Vapnik as a novel solution to the two-group classification problem (Cortes & Vapnik, 1995). The main aim of the algorithm is to find the optimum classifying boundary line (hyperplane) that has the maximum distance between the instances of either class (Kirk, 2014). The computation of the algorithm winds up to a simple quadratic system that is cheap computationally. The mathematical foundation of the algorithm is beyond the scope of this introductory paper. However, you can refer to the excellent study of Burges (Burges, 1998).
The algorithm also overcomes the problem of the inseparable training datasets and the non-linear datasets that can’t be separated by a single surface by applying what’s called, the Kernel Functions or the Kernel Tricks (Bell, 2014; Kirk, 2014; Marsland, 2015). The Kernel functions transform the datasets from a two-dimensional space to higher dimensional space. After transforming into a sufficiently appropriate number of dimensions, the same technique can be applied. “A linear separation in feature space corresponds to a non-linear segregationin the original input space (Kotsiantis, Zaharakis, & Pintelas, 2006)”. Choosing the kernel function applied and the number of dimensions outputted has a substantial effect on the performance of the classifier (Smola, Schölkopf, & Müller, 1998). Support Vector Machines algorithms can be used in the business optimization context as proposed by Yang, et.al(Yang, Deb, & Fong, 2011). It’s also utilized in the measuring retail companies’ performances and predicting financial distress situations (Fan, 2000; Hu & Ansell, 2007).
Decision Trees
Decision Trees are supervised machine learning algorithms that chiefly aims at producing a model that predicts the classification of an instance by sorting it through a flowchart-like classification model that is learned from the training datasets (Mitchell, 1997; Rokach & Maimon, 2014). The output model can be presented as a consecutive set of if-statements. Each node of the represent an attribute by which the data can be further separated into branches each of which is a possible value of the tested attribute and the data keeps branching until it reaches a leaf (Mitchell, 1997). There are two types of the decision trees: Classification Trees, in which the final leafs of the trees are discrete elements or classes, and Regression Trees, in which the output is a real value or number such as a house number (Loh, 2011). In this paper, we’ll discuss on the classification trees and more specifically, the Iterative Dichotomiser 3 (ID3) algorithm.
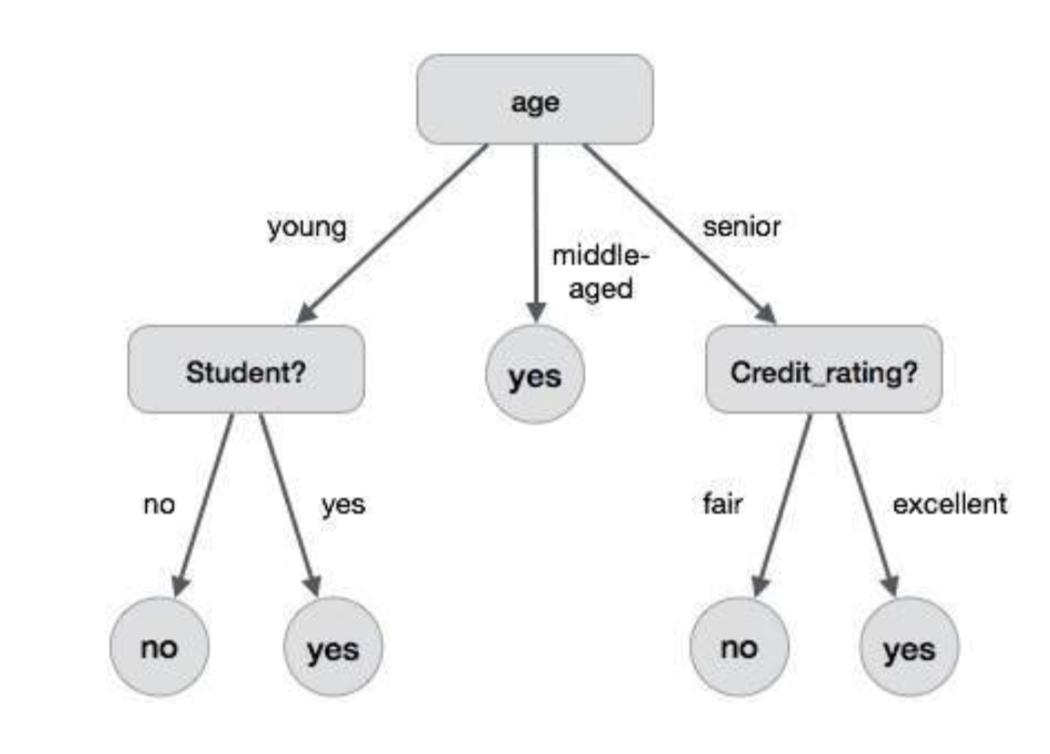
The algorithm starts off trying to find the best attribute that should be tested at the root node of the decision tree. To do that, we have to define two statistical concepts: Information Gain and Entropy. Entropy is the measure of impurity and unpredictability of the information and it ranges from zero to one; zero being that there are no impurities and that all the training data belongs to one class. Information gain, however, is the measure of how well a property is able to segregate the training datasets towards the target classifications. Information gain can be presented as the expected reduction in entropy as a result of separating the data according to a certain property or attribute. The property with the highest score of information gain is then placed at the root node of the decision tree (Mitchell, 1997). The process then repeated for each set of data passed through the branches until the leaf nodes are reached. Decision Trees are subject to the overfitting problem where the algorithm doesn’t map the underlying relationship but rather describes and adapts too perfectly to the datasets in a manner that the algorithm wouldn’t be applicable on real word (Marsland, 2015). This problem causes the algorithm to lose accuracy and reliability (HSSINA, Merbouha, Ezzikouri, & Erritali, 2014; Mitchell, 1997). Many techniques have been developed to address this issue such as the method known as the reduced error pruning. Pruning a decision node means to detach the subtree rooted at the node making it a leaf node with the value of the average classification of the items related to it. The pruned branches are removed if the algorithm validated that it didn’t perform any worse before removing it (Mitchell, 1997). Decision trees algorithm can be used guide the decision-making process as it help describe the problems understudy in a systematic and structured fashion.
Machine Learning Scenarios and Applications in the Retailing Business
As the computing power exponentially increases, machine learning gains more momentum as it becomes more practicable and implementable. The current computation power is capable of reliably storing and analyzing tremendous amount of data –Big Data-, allowing for more complex machine learning models to be implemented. However, many of the research in machine learning is done for the sake of machine learning. Many researchers tend to concentrate their work on further perfecting the performance of the existing algorithms (Wagstaff, 2012). However, not much of the research communicates back to the originating problems and domains. The following section will present some of the current and potential uses of machine learning in the retailing business, presenting recent works and publications in an attempt to fill in the gap that’s capping the impact that machine learning can offer. Machine learning can be used in business to optimize sales, improve marketing strategies, forecast sales and revenue, and to predict and analyze the risks that businesses may endure. According to research conducted by Accenture Institute for High Performance upon enterprises with $500M or more in sales, 76% of the companies are investing in machine learning research and are targeting higher sales growth in their businesses with Machine learning(Wilson, Mulani, & Alter, 2016). Machine learning gives companies and enterprises the opportunity to finally put the data they collect throughout the years to use (Columbus, 2016); to transform the data into useful information and insights that drives the future of their businesses.
Recommendations
Almost all the online shopping services that retailing companies provides uses machine learning and recommender systems algorithms (Cho, Kim, & Kim, 2002; Kim & Ahn, 2008; Senecal & Nantel, 2004). It extends the domain of big data analytics and allows for an exceptional shopping experience. As the algorithms learn more about the users, it will be able to match buyers and sellers based on the customer’s need and the product availability. Recommender systems can also be used to simplify the heavy-lifting processes and operations for the businesses. It can also be used to ensure that the stores are adequately stocked based on the predicted shopping trends of the population surrounding them and recommend and optimize the prices of the products and the shelf placement. (Walter, Battiston, Yildirim, & Schweitzer, 2012) propose a recommender system that can be put into action in retail stores. The proposal involves smart carts with chip readers to identify the items in the cart and authenticate the shoppers through their loyalty cards. The carts would recommend items to the shopper and predict items that they may have missed. Also, Recommender System algorithm can be used at the store level to recommend products based on the demographics of the customers and the location of the store (Giering, 2008). The North Face brand already tapped into the powers of the recommender systems machine learning algorithms and utilized the IBM’s Watson API to combine recommender systems with Natural-Language Processing (NLP) to provide a personal assistant buyer to their online customers (O’Rourke, 2016). A shopper can simply say or type, “I’m going on a skiing trip next week in Colorado.” The system will fuse its collection of products with weather forecasting data, the buyer’s preferences and shopping history to provide a personalized and a unique shopping experience (Gaudin, 2016).
Price Optimization
Many research has been done on the price-based revenue management. (Özer & Phillips, 2012; Talluri & Van Ryzin, 2006). Employing dynamic pricing strategy was found to achieve higher revenue (Surowiecki, 2014). Dynamic Pricing can take into account the demand on the product, the competitor pricing and other factors and machine learning will always be able to accommodate those needs. Many retails and businesses such as 7-Eleven, O’Reilly Auto Parts, and many others (Shish, 2015)are leveraging machine learning algorithms to implement those techniques. Also many research was conducted to develop and implement pricing decision support tools for retailers (Ferreira, Lee, & Simchi-Levi, 2015). Caro and Gallien (2012) address the challenge of optimizing and recommending price changes in the fashion retail business, where items are aimed to have short product life cycle. The proposed system replaced the manual, informal process that was in place in the fashion company, Zara, and increased their revenue by 6%. This work is the first large-scale, multi- product price optimization machine learning model in which all the technical and implementation details along with the impact results are available to the public. Extensive literature review on the topic can be found in (Özer & Phillips, 2012; Talluri & Van Ryzin, 2006; Van Ryzin & Talluri, 2005).
Sales and Marketing Campaign Management.
Fraud Prevention
Conclusion
Machine Learning is no longer the preserve of researchers; It has been involved in many applications and innovations in different technological and commercial domains. The massive bulk of big data boosted the potential of what it can achieve. Machine learning algorithms differs from normal algorithms in the sense that they are not very predictable, making it harder to debug and improve. Many strategies and techniques, however, are developed to tune the algorithms and identify the areas of improvements for the models to accurately operate. Data Analytics, seizing a huge sector of the all the business decision-making process, opens the doors wide open for machine learning to be perceived as the analytic tool that perfectly fits the world of big data. Businesses started utilizing machine learning models to extract new insights and to shape their strategic visions of their operations. This paper gives a brief introduction to the field and presents some of the common algorithms, elucidating their processes and steps. It also lists the different types of learning styles, explaining the major differences in their logic and tasks that they can perform. Finally, the research presents some of the applications and uses of machine learning in the public retailing business. Machine Learning has the potential to break down many of the limits induced by the traditional analytical approaches and grants the organizations the opportunity to make well- informed decisions. Many organizations have already put machine learning models into action and banked significant portion of their operations on it. It’s important to keep in mind that despite all the current advancements and capabilities of machine learning, it is yet to replace the human judgment and executives should begin to keep up with the advances in the field lest they fall far behind and endanger the continuity of their businesses.
References:
Software design pattern - Wikipedia Bell, J. (2014). Machine Learning: Hands-on for developers and technical professionals: John Wiley & Sons.
Bose, I., & Mahapatra, R. K. (2001). Business data mining—a machine learning perspective. Information & management, 39(3), 211-225. doi:Doi 10.1016/S0378-7206(01)00091-X
Burges, C. J. (1998). A tutorial on support vector machines for pattern recognition. Data mining and knowledge discovery, 2(2), 121-167. doi:Doi 10.1023/A:1009715923555
Caro, F., & Gallien, J. (2012). Clearance pricing optimization for a fast-fashion retailer. Operations Research, 60(6), 1404-1422.
Cho, Y. H., Kim, J. K., & Kim, S. H. (2002). A personalized recommender system based on web usage mining and decision tree induction. Expert Systems with Applications, 23(3), 329- 342.
Columbus, L. (2016, June 4, 2016). Machine Learning Is Redefining The Enterprise In 2016. Forbes Magazine.
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3), 273-297. doi:10.1007/bf00994018
Fan, A. (2000). Selecting bankruptcy predictors using a support vector machine approach. Paper presented at the Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks (IJCNN'00)-Volume 6-Volume 6.
Ferreira, K. J., Lee, B. H. A., & Simchi-Levi, D. (2015). Analytics for an online retailer: Demand forecasting and price optimization. Manufacturing & Service Operations Management, 18(1), 69-88.
Gaudin, S. (2016). The North Face sees A.I. as a perfect fit. Retrieved from Computerworld website:
Giering, M. (2008). Retail sales prediction and item recommendations using customer demographics at store level. ACM SIGKDD Explorations Newsletter, 10(2), 84-89.
Hartigan, J. A., & Wong, M. A. (1979). Algorithm AS 136: A k-means clustering algorithm. Journal of the Royal Statistical Society. Series C (Applied Statistics), 28(1), 100-108.
HSSINA, B., Merbouha, A., Ezzikouri, H., & Erritali, M. (2014). A comparative study of decision tree ID3 and C4. 5. Int. J. Adv. Comput. Sci. Appl, 4(2).
Hu, Y.-C., & Ansell, J. (2007). Measuring retail company performance using credit scoring techniques. European Journal of Operational Research, 183(3), 1595-1606. doi:http://dx.doi.org/10.1016/j.ejor.2006.09.101
Kim, K.-j., & Ahn, H. (2008). A recommender system using GA K-means clustering in an online shopping market. Expert Systems with Applications, 34(2), 1200-1209.
Kirk, M. (2014). Thoughtful Machine Learning: A Test-driven Approach: " O'Reilly Media, Inc.".
Kotsiantis, S. B., Zaharakis, I. D., & Pintelas, P. E. (2006). Machine learning: a review of classification and combining techniques. Artificial Intelligence Review, 26(3), 159-190. doi:10.1007/s10462-007-9052-3
Loh, W. Y. (2011). Classification and regression trees. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 1(1), 14-23. doi:10.1002/widm.8
Lu, C.-J., & Kao, L.-J. (2016). A clustering-based sales forecasting scheme by using extreme learning machine and ensembling linkage methods with applications to computer server. Engineering Applications of Artificial Intelligence, 55, 231-238. doi:10.1016/j.engappai.2016.06.015
Maglogiannis, I. G. (2007). Emerging artificial intelligence applications in computer engineering: real word AI systems with applications in eHealth, HCI, information retrieval and pervasive technologies (Vol. 160): Ios Press.
Marsland, S. (2015). Machine learning: an algorithmic perspective: CRC press.
Mitchell, T. M. (1997). Machine learning. 1997. Burr Ridge, IL: McGraw Hill, 45, 37.
O’Rourke, J. (2016). How Machine Learning Will Improve Retail and Customer Service[Retrieved from Data Informed website: http://data-informed.com/how-machine- learning-will-improve-retail-and-customer-service/
Özer, Ö., & Phillips, R. (2012). The Oxford handbook of pricing management: Oxford University Press.
Rokach, L., & Maimon, O. (2014). Data mining with decision trees: theory and applications: World scientific.
Senecal, S., & Nantel, J. (2004). The influence of online product recommendations on consumers’ online choices. Journal of retailing, 80(2), 159-169.
Shish. (2015). Big Data & Machine Learning Scenarios for Retail. Retrieved from Microsoft Developer Blog website: https://blogs.msdn.microsoft.com/shishirs/2015/01/26/big-data- machine-learning-scenarios-for-retail/
Smola, A. J., Schölkopf, B., & Müller, K.-R. (1998). The connection between regularization operators and support vector kernels. Neural networks, 11(4), 637-649. doi:Doi 10.1016/S0893-6080(98)00032-X
Surowiecki, J. (2014). In praise of efficient price gouging.
Talluri, K. T., & Van Ryzin, G. J. (2006). The theory and practice of revenue management (Vol. 68): Springer Science & Business Media.
Van Ryzin, G. J., & Talluri, K. T. (2005). An introduction to revenue management. Tutorials in operations research, 142-195.
Wagstaff, K. (2012). Machine learning that matters. arXiv preprint arXiv:1206.4656.
Walter, F. E., Battiston, S., Yildirim, M., & Schweitzer, F. (2012). Moving recommender systems from on-line commerce to retail stores. Information Systems and E-Business Management, 10(3), 367-393. doi:10.1007/s10257-011-0170-8
Wilson, H. J., Mulani, N., & Alter, A. (2016). Sales Gets a Machine-Learning Makeover. MIT Sloan Management Review, May, 17.
Wu, J. (2012). The Uniform Effect of K-means Clustering Advances in K-means Clustering (pp. 17-35): Springer.
Yang, X.-S., Deb, S., & Fong, S. (2011). Accelerated Particle Swarm Optimization and Support Vector Machine for Business Optimization and Applications. In S. Fong (Ed.), Networked Digital Technologies: Third International Conference, NDT 2011, Macau, China, July 11- 13, 2011. Proceedings (pp. 53-66). Berlin, Heidelberg: Springer Berlin Heidelberg.